


執筆者:鳥海俊輔
1. AI時代は「良いデータ」が最も高価な資源になった
AI技術の進化は、モデル開発競争からデータ戦争へと主戦場を完全に移した。大規模言語モデル(LLM)の性能が頭打ちになりつつある現在、GPUの次にAI企業が巨額の投資を行っているのは、モデルを訓練するための良質な訓練データである。特に、LLMが真に実務で活用されるためには、単なる大量のテキストデータではなく、専門家の思考データ(法律、医療、金融など)が不可欠となり、その価値は爆発的に高まっている。
この文脈において、世界中のAIラボの「裏側」を支え、設立3年足らずで評価額100億ドルに達したのが、データプラットフォームのMercor(メルコア)だ。Mercorは、世界中のトップクラスの専門家を動員し、彼らの知的労働をAI訓練データへと変換する新たな産業を創出した。これは、AIが人間の知性を代替するのではなく、人間がAIを育てるという新たな労働市場の創造であり、この「人間データ工場」の戦略を深く分析することは、AI時代の投資戦略において不可欠となる。本稿では、Mercorのデータ収集戦略とオペレーションの革新である「思考のデータ化」を詳細に解き明かし、その戦略を日本市場で応用する際の戦略的困難さと、日本固有の勝ち筋を考察する。

2. Mercor(メルコア)とは何か?
Mercorは、CEOのBrendan Foody氏、CTOのAdarsh Hiremath氏、会長のSurya Midha氏の3名によって創業された。元々は「AI面接」プロダクトとしてスタートしたが、現在は専門家データプラットフォームへとピボットし、OpenAI、Anthropic、Big Techといった大手AI研究機関のモデル訓練を支える存在となっている。
Mercorの核となるのは、世界中のホワイトカラー専門家(博士号取得者、弁護士、金融プロなど)約3万人を擁する「専門家クラウド」だ。Mercorは日々、150万ドル以上もの報酬を専門家に支払いながら、AIモデルに人間の判断力やニュアンスを教え込むためのデータ生産に従事している。
Mercorは“人間の頭脳をデータ化する工場”である。
この工場は、必要な専門家を必要なときに即座に集められる調達力と、その知的労働を効率的にデータ化するオペレーションによって支えられている。Mercorは、2024年初頭までに10万人のホワイトカラー専門家を面接し、膨大な人材プールを確保しており、その成長速度は「史上最速でARR5億ドルに到達した会社」と評されるほどだ。
3. Mercorが集めているデータの種類
Mercorが集めるデータは、その深さと専門性において、従来のデータラベリング企業とは一線を画す。特に、単なる「正解」ではなく、「正解に至るまでの思考プロセス」をデータ化している点が、LLMの性能向上に決定的な役割を果たしている。
3-1. 専門家プロフィール・面接データ
これは、Mercorのデータ生成オペレーションの品質を担保する最初の資産である。
・履歴書、経歴、資格: 専門領域やスキルタグに基づき、最適な人材をタスクにマッチングさせるための基礎情報。
・AI面接データ: 応募者選考の際にAIアバター面接官が候補者と対話し、応答を評価するプロセスで、面接動画、音声、文字起こし、ケース回答とロジックの構造化データが収集される。
・選抜された専門家: 元ゴールドマン・サックスの投資銀行家、マッキンゼーのコンサルタント、著名ローファームの弁護士など、各業界のトップ人材を積極的に勧誘し、契約者として囲い込んでいる。
→ 「誰をデータ生成に使うか」を最適化するための資産。
3-2. 専門家の実務タスク(法律・医療・金融・CS・営業)
Mercorのメイン商品は、各分野の専門家が実務さながらのタスクを遂行する過程で生成される、深い専門知識と判断理由がセットになったデータである。
■ 法律領域
法律相談シナリオ(例:著作権相続のトラブル)に対し、専門家が
- 論点整理
- 結論
- 適用すべき判例や法的根拠
までを記述する。
また、契約書レビューでは、
- リスクのある条文の抽出
- なぜその条文が問題なのか
- どう修正すべきか
といった解説までセットで収集する。
法的推論の流れとリスク判断の基準を丸ごとデータ化する点が特徴である。
■ 医療領域
医師には、症例ベースの診断タスクが与えられる。
(例:6歳患者の複数の検査結果を提示し、診断→治療方針→理由まで記述させる)
看護領域では、急変兆候の判断やケアプラン決定のプロセスなど、
- 状況から何を優先して判断したか
- どの情報を重視したか
といった臨床判断の流れを含めたデータが収集される。
医療現場の優先度判断・推論のプロセスがそのままデータ化される点が価値となる。
■ 金融/コンサル領域
投資銀行やコンサル出身者には、
- 企業価値評価(DCF/LBO)
- その前提条件
- 想定リスクと感応度分析
- 最終的な投資判断とその理由
といった業務を実行させる。
監査・財務分析分野では、報告書のレビューや修正タスクも含まれる。
高度な財務モデリングと意思決定の背景がデータとして取得される。
■ カスタマーサポート/営業領域
CS領域では、顧客対応チャットやクレーム処理の会話ログに対して、
- どこが適切だったか
- どこが改善すべきか
- より望ましい対応案
などを専門家がフィードバックする。
営業領域では、反論処理やロールプレイに対し、
- より効果的な返し
- 想定される顧客心理
- 改善案
を記述させる。
現場に即した対話スキルとベストプラクティスが含まれた実務データとなる。
3-3. 実務ワークフロー・推論ログ・行動ログ
Mercorの真の競争優位性の源泉は、単なる知識ではなく、「人間の思考プロセス」というメタ情報をデータ化している点にある。
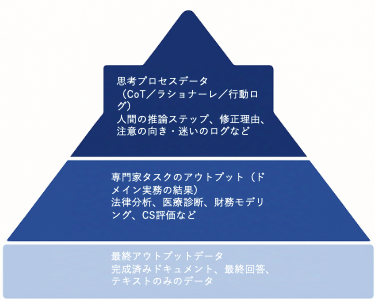
1. 思考プロセス(Chain-of-Thought/Rationale)の回収
・推論の連鎖(CoT)の言語化: 専門家は、最終回答だけでなく、その判断に至る根拠や推論ステップを段階的に文章化するよう指示される。例えば、「まず○○の事実に注目し、次に△△という基準で評価した。その結果□□との結論に至った」という思考の連鎖を記録する。
・判断理由の明示: 「なぜその答えが正しいのか」「他に検討すべき論点は何か」といった背後の理由づけが回答とセットで記録される。これは、モデルに人間の考え方の筋道を教え、より説明可能で一貫した推論を可能にする狙いがある。
2. 修正履歴と判断理由の記録
・誤答から正答へのプロセス: 専門家がAIの出力を精査し、誤りを指摘・修正する際、「どこを誤りと判断し、どう修正したか」という修正履歴データも逐一記録される。これにより、モデルは誤答から正答への修正プロセスを学習し、自ら回答を見直し改善する能力(セルフリファインメント)を強化できる。
3. 実務ワークフローと行動ログの数値化
・実務ワークフロー: 医療診断のフロー、契約レビューの段取りなど、実務における意思決定の順序や、どの情報に注目すべきかという「業務の型」をデータとして収集する。
・行動ログの収集: どこで迷ったか、何秒かかったか、どの観点を見落としたかといった「人間の癖」や「思考プロセスの数値化」につながる行動ログも収集されていると推測される。
→ “人間の癖”まで学習できる超高付加価値データ。
4. Mercorはどのようにデータを集めているか(オペレーション)
Mercorのオペレーションは、専門家ネットワークをフル活用してAI訓練用データを大量生産するよう設計された「人間データ工場」だ。鍵となるのは、タスクの細分化と並列実行、そしてプラットフォームによる集中管理である。
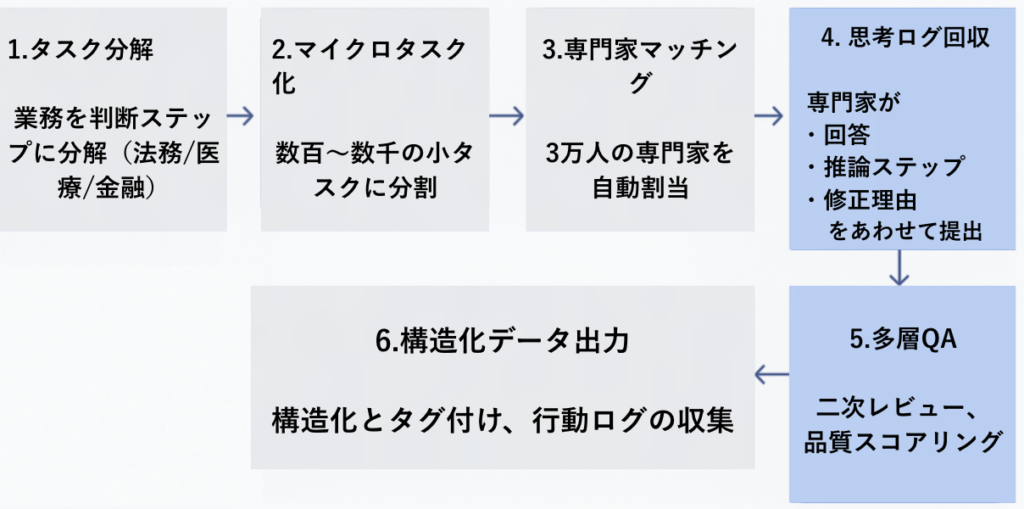
4-1. AI面接+スクリーニング
Mercorは、AIを活用した選考プロセスで、専門家の質を担保し、オンデマンドな人材調達力を実現している。
・AI面接官によるスクリーニング: AIアバター面接官が候補者と対話し、履歴書や想定業務に基づいた質問を自動生成して応答を評価する。これにより、短時間で大量の応募者をスクリーニングし、優秀な専門家を選別している。
・人材プール: 2024年初頭までに10万人のホワイトカラー専門家を面接し、膨大な人材プールを確保している。
4-2. 専門家に実務タスクをやらせる
Mercorは、クライアントが求める実務に即したタスクを設計し、専門家に実行させることで、単なるラベルではなく思考ログを回収する。
・タスク設計と配信: プロジェクト開始時に、実務に即した専門タスクを定義し、Mercorのプラットフォームがスキルタグに基づき最適な契約専門家をマッチングし、タスクを配信する。
・思考ログの回収: 専門家には、最終回答だけでなく「どのように判断したか説明してください」といった指示が与えられ、回答、修正案、評価、理由のすべてを記述させる。
・対話形式によるデータの深掘り収集: AI面接の要領で、AIが専門家に追加質問を投げかけ、専門家が答えていく1対1の疑似対話データが作られる場合がある。さらに、高度なタスクでは専門家間ディスカッション(一人の回答に対し別の専門家がコメントし、議論のログを取得)も検討されている。
4-3. AI回答を添削・採点させる(RLHF/RLAIF)
Mercorは、強化学習(RLHF/RLAIF)に必要なデータを効率的に大量生成する仕組みを確立している。
・モデル出力の評価・修正: 専門家は、複数AIの回答を提示され、良し悪しのスコア、ランキング、そして修正版と修正理由を出す。
・フィードバックループの構築: 専門家がモデルのミスを指摘・修正し、そのデータでモデルを再訓練するという人間とAIの反復プロセスが回っている。Mercorは、モデルの判断を人間が検証して報酬付けする(強化学習:RLHFの基礎となる)一連のプロセスをソフトウェアで支援し始めている。
4-4. 多段QA
データ品質の確保は、Mercorの信頼性の根幹だ。多層的なレビュー体制とインセンティブ設計によって、高品質を担保しながらスケールを実現している。
・多層的なレビュー: 契約専門家による一次データは、直ちに別のシニア専門家や社内レビュアーによってチェックされる。特に優秀な人材をリードアノテーターに任命し、他の専門家の作業内容を評価・指導させている。
・クロスチェック: 高度なタスクでは、複数名の独立した専門家に同一タスクを実施させ、回答を突き合わせることでデータの正確性と一貫性を高めている。
・品質スコアリングとインセンティブ: 契約アノテーターの評価指標(スコア)を設け、品質に応じて報酬面でボーナスを支給する仕組みがある。
4-5. 行動ログ・構造化
・構造化とタグ付け: 収集されたデータは、AIが学習しやすいよう厳密に構造化・タグ付けされる。長文の解答内であっても、段落ごとに推論ステップやエビデンス参照といったラベルを付け、モデルが注目すべき情報を学習しやすくする。
・行動ログの収集: どこで迷ったか、何秒かかったか、どの観点を見落としたかといった行動ログを収集し、思考プロセスの数値化を試みている。
5. 日本の勝ち筋:業界特化と「思考が貯まる事業設計」
Mercorの成功モデルは、日々150万ドル以上を専門家に支払い、3万人を囲い込むという圧倒的な資本力とネットワーク効果によって成り立っている。したがって、多額の資金がかかる汎用的な専門家クラウドプラットフォームを後発で日本から構築し、Mercorと同じ土俵で戦うことは、戦略的に極めて困難である。日本市場の勝ち筋は、Mercorの「人間の思考をデータ化する」という核心的な思想を、特定の業界・用途に特化した事業設計に組み込むことにある。
Mercorの成功から学ぶべき核心は、「人間の思考をデータ化する」という思想であり、これを日本の市場環境と結びつけることが、突破口となる。
5-1. 「人間の思考」が貯まる事業設計の重要性
AIを活用した事業において、単に業務効率化のツールを提供するだけでは、データは「結果」としてしか残らない。しかし、MercorがCoT(思考の連鎖)を回収したように、「なぜその結果に至ったか」というプロセスをデータとして残すワークフローを設計することで、その事業は持続的な競争優位性を獲得する。
具体的に、ワークフロー設計が「結果のみを記録」する構造になっている場合、貯まるデータは最終的なアウトプット(例:契約書の最終版)のみであり、LLMの推論能力向上に寄与しないため、競争優位性は低い。これに対し、「思考プロセスを記録」する構造では、最終アウトプットに加えて、修正理由、判断根拠、行動ログといったメタ情報が貯まる。このデータは、モデルの推論力、説明可能性、実務適用性を向上させるため、競争優位性は極めて高くなる。
5-2. 金融・コンサル業務を例とした「思考が貯まる」ワークフロー設計
具体的な専門業務を例に、思考がデータとして貯まる設計と、そうでない設計を比較する。

【悪い設計例:結果のみが貯まる】
・業務: 金融アナリストがAIの生成した企業評価レポート(DCFモデル)を修正する。
・ワークフロー: AIが「リスク感応度」や「前提条件」を提示 → アナリストがExcelやWordで数値を修正 → 最終版のレポートを保存。
・貯まるデータ: 最終的な企業評価レポートと、AIが提示した初期の数値(結果)。
・問題点: アナリストが「なぜこの成長率を下方修正したか」「なぜこのLBOの前提条件を厳しくしたか」という思考(判断理由)がデータとして残らない。AIは修正後の結果しか学習できず、市場の変化に対する判断のロジックを学習できない。
【良い設計例:思考がデータとして貯まる】
・業務: 金融アナリストがAIの生成した企業評価レポート(DCFモデル)を修正する。
・ワークフロー: AIが「リスク感応度」や「前提条件」を提示 → アナリストが専用プラットフォーム上で修正 → 修正時に「修正理由」「市場環境の根拠」「リスク感応度の再評価」をプルダウンやテキスト入力で強制的に記録させる。
・貯まるデータ: 最終版 + アナリストの思考ログ(修正理由、根拠、評価)。
・優位性: この思考ログが、そのまま実務特化LLMのCoTデータとなり、モデルは「なぜその判断が必要か」という人間の判断ロジックを学習できる。このデータを持つ企業は、競合に対して圧倒的な優位性を確立する。
5-3. 日本の勝ち筋は「業務特化LLM」と「事業設計」の融合
日本のAI戦略は、Mercorのような汎用的なプラットフォームを追うのではなく、業界特化のSaaSやBPO事業を通じて、この「思考が貯まるワークフロー」を顧客の業務に深く組み込むことにある。
1.事業設計: 顧客の業務フローに、AIによる推論と、専門家(現場担当者)による「思考の言語化」を強制するステップを組み込む。
2.データ資産化: その過程で生成された「思考ログ」を、顧客の許可を得て匿名化・構造化し、実務特化LLMのファインチューニングに活用する。
3.価値回収: 強化されたLLMをSaaSとして提供することで、顧客の業務効率をさらに向上させ、データ資産の価値を事業収益として回収する。
→ 「人間の思考」をデータ化する事業設計こそが、日本市場におけるAIスタートアップの最も筋の良い戦略となる。
6. まとめ(データ戦争の時代と日本のチャンス)
AI時代の主戦場はモデルではなく、「人間の思考データ」だ。Mercorはそのど真ん中に位置し、専門家の思考プロセスをデータ化する「知の工場」を築き上げた。
しかし、後発企業がMercorと同じ土俵で戦うことは、戦略的に困難である。日本が勝つには、米国とは異なる戦略的アプローチが必要となる。
それは、Mercorの成功の核心である「人間の思考をデータ化する」という思想を、業界特化の事業設計に組み込むことだ。
結局は、「どのデータ資産を構築するか」ではなく、「人間の思考がデータとして貯まるワークフローをいかに事業設計に組み込むか」が、AI戦略の核心となる。日本市場においては、特定の業務プロセスに深く入り込み、AIによる推論と専門家による「思考の言語化」を強制する「思考が貯まる事業設計」こそが、最も筋の良い勝ち筋となるだろう。
「生成AI起業のヒント」では、ANOBAKAが注目している海外の生成AIスタートアップを取り上げて、生成AIの活用方法を分析・解説していきます。
生成AI領域で起業を考えられている方にとって事業のヒントとなれば幸いです。
ANOBAKAでは、日本において生成AIビジネスを模索する起業家を支援し、産業育成を実現する目的で投資実行やコミュニティの組成等を行う、生成AI特化のファンドも運用しております。
生成AI領域で起業したい、ANOBAKAメンバーと話してみたいという方はぜひお問い合わせよりご連絡ください!
お問い合わせ


