


こんにちは!お久しぶりです!
インターンの川野(@_takamasaaaaa_)です!
「生成AI起業のヒント」では、ANOBAKAが注目している海外の生成AIスタートアップを取り上げて、生成AIの活用方法を分析・解説していきます。
生成AI領域で起業を考えられている方にとって事業のヒントとなれば幸いです。
第25弾となる本記事では、次世代言語モデルを独自開発するContextual AIというスタートアップを紹介します!
1. Contextual AIとは

■企業情報
- 会社名:Contextula AI
- 本社所在地:マウンテンビュー(アメリカ)
- 最新の調達ラウンド:Series A
- 資金調達総額:1億ドル
- 主な株主:Snowflake Ventures, NVentures, Recall Capital, Lightspeed Venture Partners, Bain Capital Venturesなど
- カテゴリー:LLM, RAG
- 公式ホームページ:https://contextual.ai/
23年6月にシードラウンドの資金調達を発表してステルスモードから浮上し、“そのベールを脱いだ”とされていたContextual AIが、今度はシリーズAラウンドで8,000万ドルの資金調達を実施したことで再びスポットライトを浴びています。
Contextual AIが関心を集めている理由ですが、それはやはり同社が提唱しているRAG 2.0という新たな技術にあるでしょう。

この技術の革新性について理解するためには、まず”RAG”とは何なのかに触れておきたいと思います。既にご存知の方は読み飛ばしてください。
RAGとは
RAGは、「Retrieval Augmented Generation」の頭文字をとった略語で、日本語では「検索拡張生成」と呼ばれています。LLMによるテキスト生成(Generation)に、外部情報を検索する技術(Retrieval)を組み合わせることで、LLMの回答精度を高める技術のことです。
LLMは、ユーザーから入力された質問やプロンプトに対して、学習済みのデータに基づいて統計的に確率が高い回答を生成します。したがって、学習データに含まれない情報や新しすぎる情報については回答することができない(情報の鮮度の問題)か、出鱈目な答えを返してくる(ハルシネーション問題)といった問題が発生していました。
そこで、2020年にFacebook AI Research(現Meta AI)に所属していたDouwe Kiela氏(Contextual AIの創業者)らは「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」という論文でRAGの基本概念を発表しました。厳密にこの技術のルーツを辿ると1970年代にまで遡るのですが、RAGという名称を明確に定義し、自然言語処理(NLP)と情報検索(IR)を結合する形で仕組みを体系化したのはこの時だと言われています。
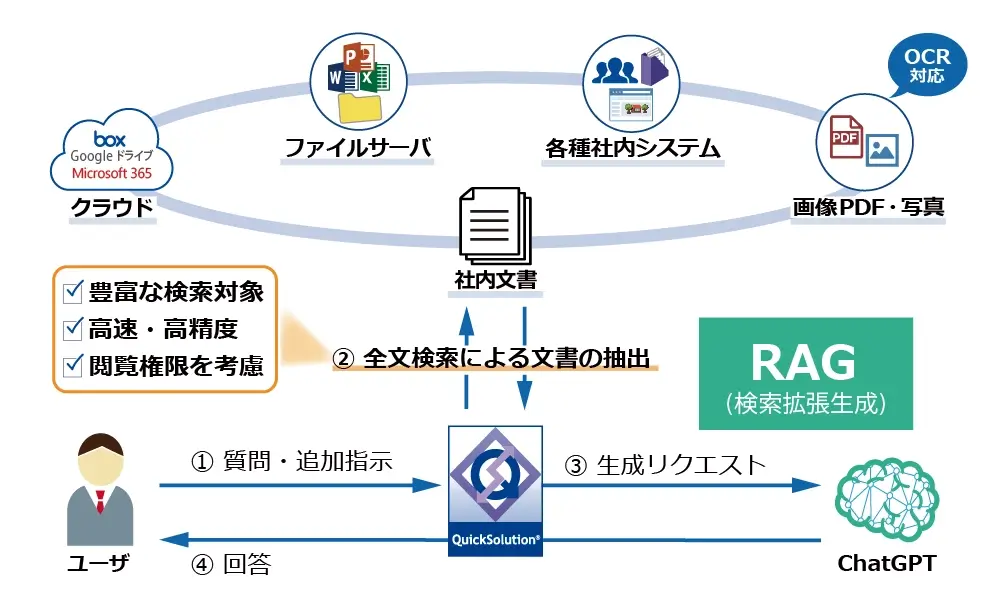
イメージしやすい例として、よく「学校のテストとカンニングペーパー」に例えられることが多いです。あらかじめカンニングペーパーを用意しておけば、勉強していない範囲から問題が出てもそのカンニングペーパーを見ることで、正しく回答することができるというイメージです。
参考:Shogo Sakamoto|Bitbloom『RAGとは?最新の情報でAIを強化する新技術』
2. 個別最適から全体最適へ
2.0というナンバリングがされているせいか、個人的には従来のRAGが1.0で、そこから”一段階アップグレードされた次世代のもの”という感覚に陥りがちですが、RAG自体は技術の進歩とともにこれまでにも何度か進化を遂げてきています。
RAGの変遷
前述したように、RAGはユーザーのプロンプトについて外部情報を検索(Retrieval)し、取得した情報に基づいて回答を生成(Generation)するというのが基本的な処理フローになります。こちらは「Naive RAG」と呼ばれる最もシンプルな構造のRAGです。
しかし、この構造ではハルシネーションの解決にはあまり効果的でなかったり、回答の正確性が担保されきれていないという明確な課題がありました。
そこで次に、検索の精度向上に焦点を当てた「Advanced RAG」と呼ばれるRAGが登場しました。Advanced RAGでは、Retrieval(検索)フェーズが①Pre-Retrieval、②Retrieval、③Post-Retrievalと細かく3つの処理に分割されています。
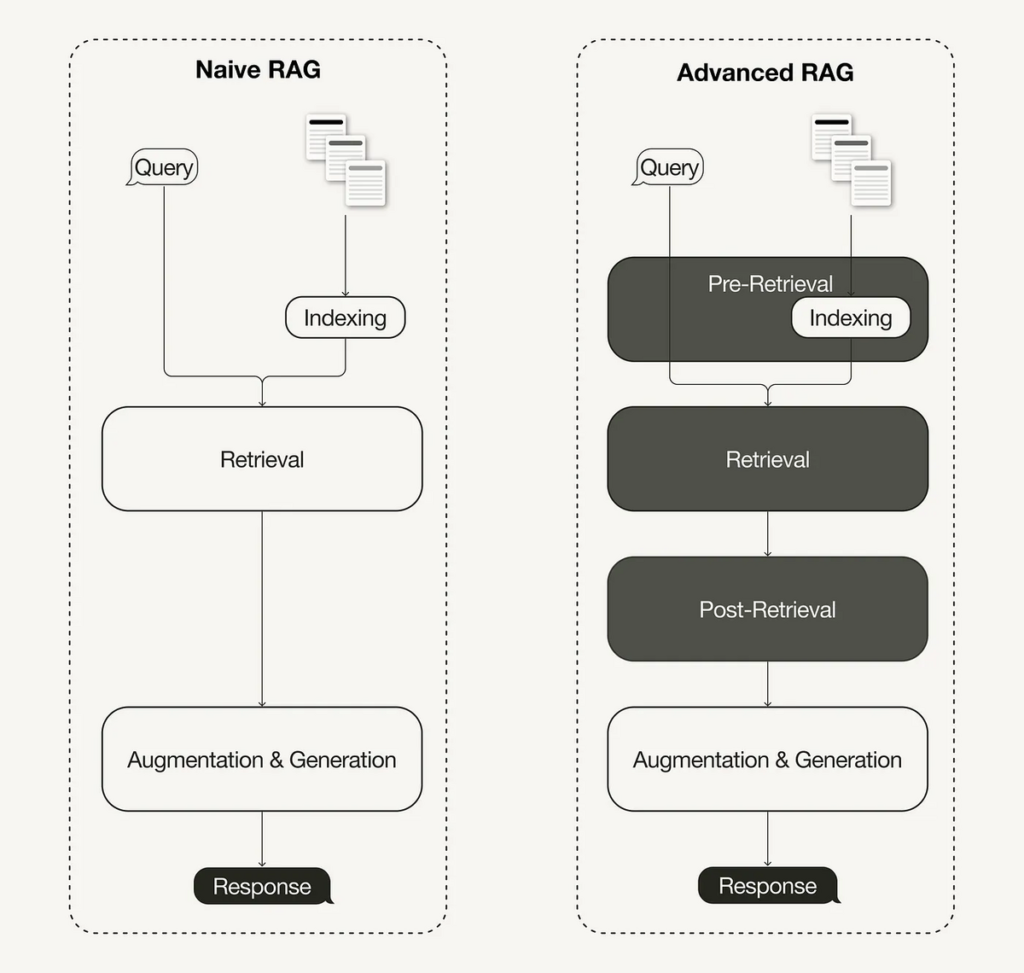
Advanced RAGにより、より高度な検索が実現した反面、技術が複雑化したり、特定のタスクや業界に特化させたいというカスタマイズのニーズが現れたりするようになりました。
そこで、各処理フローにおける細かな機能をそれぞれモジュールとして切り出し、モジュール単位での最適化や、柔軟なカスタマイズを実現することができる「Modular RAG」が登場しました。
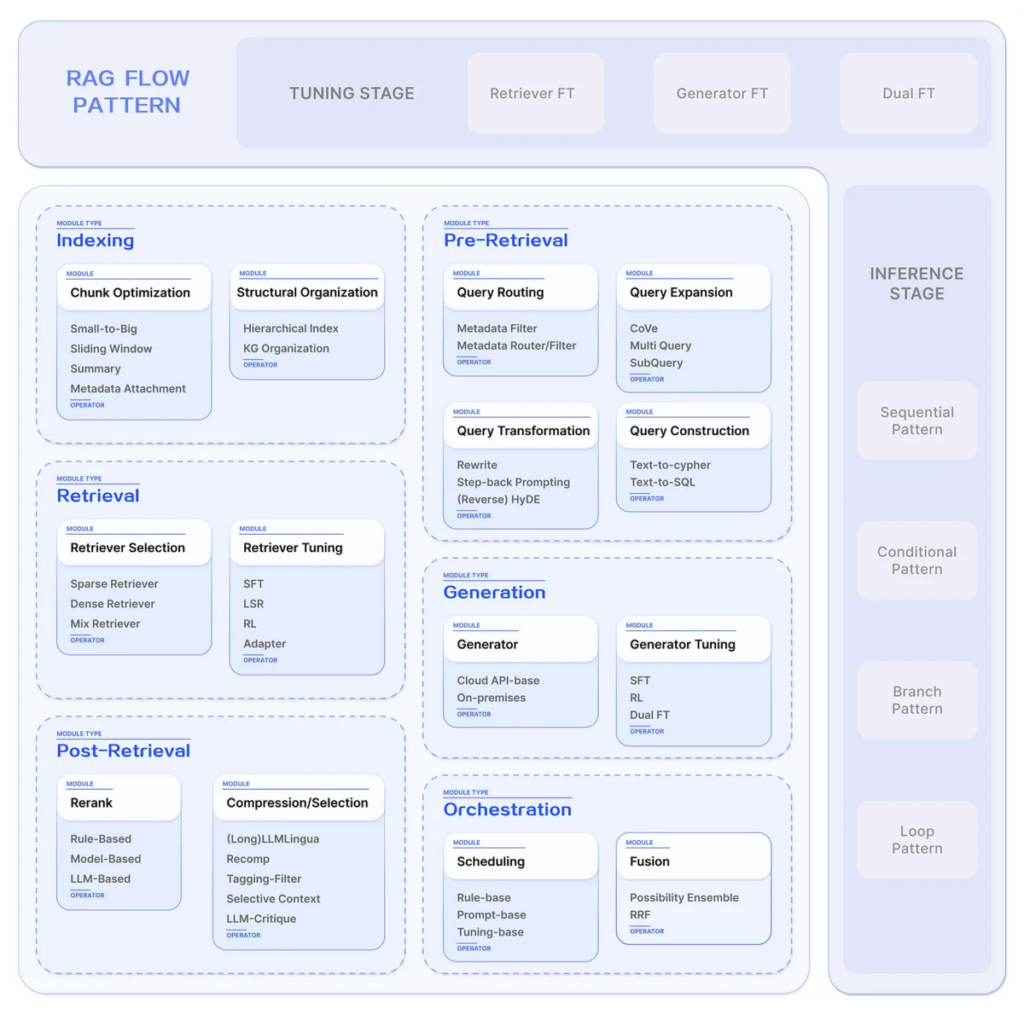
このような変遷を経て、現在のRAGでは、基本的な処理フローは変わらずとも、主要な機能がモジュールとして独立しており、モジュール同士の組み合わせによる構築が主流となっています。
確かに、個々のモジュールは技術的には問題なく動作していますし、カスタマイズの柔軟性やトレーニングの効率性を考えると合理的に思えます。
しかし、個々のモジュール単位でトレーニングされているということは、個別最適化こそされてはいるものの、それらを組み合わせても全体最適にはならないということでもあります。ここがまさに従来のRAGの大きな課題で、あたかも有名な怪物の「フランケンシュタイン」のごとく、継ぎ接ぎされただけのシステムは脆弱であり、パフォーマンスの面でも実際の運用基準を満たすことはできていませんでした。
参考:
・Re:ゼロから始めるML生活『Naive RAGからModular RAGまで』
・ますみ / 生成AIエンジニア『RAGの処理フロー【In-Context Learning / Embedding / Vector Search】』
“全体最適”を目指すContextual AI
RAG 2.0の特筆すべき特徴であり、従来のRAGから最も大きく変化した点が、全体を単一の統合システムとして捉え、各処理フローが緊密に連携することでシステム全体として最適化していく点です。
“フランケンシュタイン”状態になっている従来のRAGでは、セキュリティの面でもパフォーマンスの面でも運用基準には至っていないと述べましたが、Contextual AIは全体最適という強みを活かすことで、ハルシネーションの軽減やハイレベルなパフォーマンス、柔軟なカスタマイズ性(より企業独自のタスク特化)といった価値を提供できると期待されています。
そして、既存の大手LLMプレイヤーとの戦い方としては、上記の強みや価値が最も効果的に刺さるであろう、エンタープライズ向けに特化していくことが初期戦略であり、中長期的にも独自のポジションを築くことができると主張しています。
Contextual AIの主力製品は、あくまでもRAGアプリケーションを簡易に構築することができるプラットフォーム(現在は未リリース)ですので、今後彼らがどのようにソリューションまで落とし込んでいくのかは注目していきたいです。
さて、RAG 2.0に話を戻して仕組みを見てみると、RAG 2.0ではまず回答精度の良し悪しを評価するべく、最終的に出力した回答と正解との“誤差”を計算します。そして、その誤差をGeneration(生成)とRetrieval(検索)の両方へ伝播させ、使用しているモデルをトレーニングしています。
このように、GenerationとRetrievalで同じ誤差を使用してモデルを同時にトレーニングすることで、一貫性と全体的な精度の両方を向上させていくことができるのです。
このように、出力層から入力層まで誤差を逆流させ、モデルを調整する手法は誤差逆伝播法と呼ばれており、もともと機械学習分野では使われてきていた技術ですが、それをRAGへ適用している形になります。
実際のところ、誤差逆伝播法を活用した全体最適アプローチがいかに効果的なのかは、他のLLMのパフォーマンスと比較すると明らかです。
※Natural QuestionsやHPQA(HotpotQAの略)、TriviaQAなどはAIモデルの評価に用いられるデータセットのことです。
上図は様々なデータセットを用いて既存の強力なRAGとパフォーマンス(正確性)を比較したグラフですが、RAG 2.0はGPT-4やMixtralといった最高レベルのオープンソースモデルに基づく強力なRAGよりも大きく上回るパフォーマンスを示しています。
自社を最も良く見せるのは普通なので鵜呑みにしてはいけませんが、新時代の幕開けにワクワクすることには変わりないです。全体最適を目指すContextual AIのアプローチは、どれほどのイノベーションを市場にもたらすのか、一気に階段を駆け上って既存のビッグプレーヤーたちと肩を並べられるのか、今後の動向に要注目です。
3. RAGの未来 in Japan
最後に、視線を日本に向けてみます。
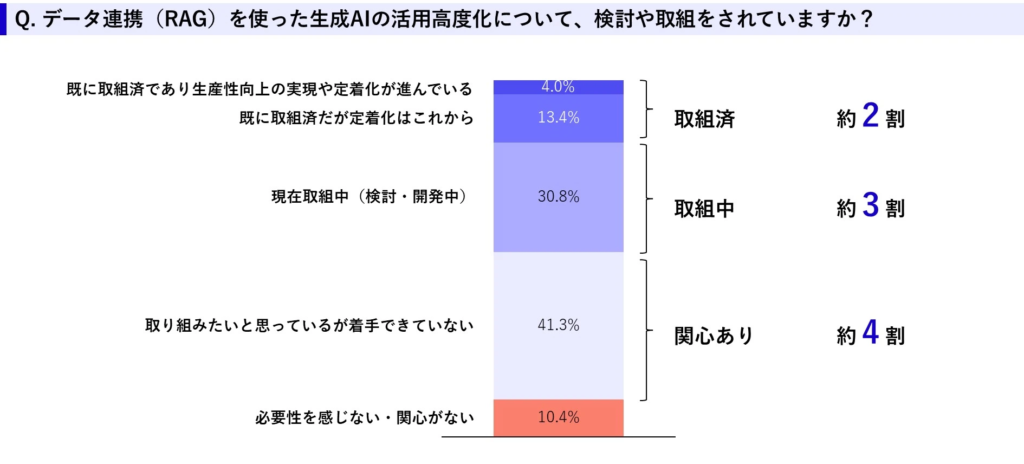
エクサウィザーズさんから発表されている調査レポートによると、RAGの業務シーンでの活用に既に取り組んでいる企業は調査対象全体の約20%ほどで、その中でも、さらに生産性向上の実現や定着化まで進行している企業となるとわずか4%となってしまうそうです。
こちらの調査は、エクサウィザーズさんが開催した生成AIセミナーへの参加者を対象に実施しているとのことなので、日本全体で見ると普及率はもっと下がるのではないかと考えています。
一方で、関心を持っているが着手できていない企業が約40%という結果も出ており、RAGのポテンシャルに対して期待を抱く企業も潜在的にはかなり存在していることもわかります。
このような企業が導入に踏み切れない大きな理由が、データベースの品質にあります。そもそもデータベースの情報が間違っていれば、そこを参照するRAGは当然誤った回答を生成します。あるいは、データベースに入っていない情報については、参照できないのでRAGとはいえ、回答することなどできません。
RAGを活用するための環境整備などと呼ぶのが正しいのかわかりませんが、直近ではここから地道に始めていくしかないのではないでしょうか。
テキストデータのベクトル化やチャンク化、メタデータの付与など、データベースの構築に使用される技術はいくつかありますが、こうした技術を活用してデータの前処理や加工を担うプレーヤーが増えてきているのは良い流れかもしれません。
ただ、あくまでRAGもRAG 2.0も何かを実現するためのツールでしかないので、技術をアプリケーションに落とし込み、誰よりも早くキラーユースケースを生み出すにはどうすれば良いのかは考え続けていきたいと思います。
答えがあるわけではないですが、議論したい!という方はぜひANOBAKAまでご連絡ください。
執筆者:川野 孝誠
ANOBAKAでは、日本において生成AIビジネスを模索する起業家を支援し、産業育成を実現する目的で投資実行やコミュニティの組成等を行う、生成AI特化のファンドも運用しております。
生成AI領域で起業したい、ANOBAKAメンバーと話してみたいという方はぜひお問い合わせよりご連絡ください!
お問い合わせ


