


著者: 中 縁嗣( @eni_naka)
ウォーレンバフェットと並ぶバリュー投資家の巨匠の一人、ピーター・リンチ氏の名言、
ゴールドラッシュで最も儲けたのはツルハシやテントのメーカーである
という話はあまりに有名です。
この名言の意図は金に目が眩んでツルハシやテントで散財をしては元も子もないということですが、Pick-And-Shovel Playと呼ばれる商品を生み出すのに必要な基盤に投資する投資戦略の名前の由来になっており、リスク低くマーケットの成長に投資できる戦略として非常に参考になります。
では1840年のアメリカでは金を採掘することがブームでしたが、現在のゴールドラッシュとは果たしてなんでしょう?
一つは猫も杓子もAIというように人工知能ブームです。画像認識、音声認識、自然言語処理、画像生成、などの機械学習の技術がさまざまなスタートアップで用いられてこれらのテーマの企業は巨額の資金調達をしています。
このような現代の金脈としてのAIのツルハシとは何にあたるのでしょう。
AIとアノテーション
AIを作る工程は教師あり学習と教師なし学習が存在し、教師あり学習でAIのモデルを作る工程では大きく4工程が存在します。
- データ収集,アノテーション
- モデル学習
- モデル実装
- モデル評価
こういった流れで作られるのですが、世にいうAI企業は2-4のモデル学習、実装、評価、運用の部分を行っている企業がメインです。
そしてこう言った企業は基本的にデータ収集、データの処理・アノテーションが必要なのでAIにおけるツルハシはトレーニングデータの収集、アノテーションの工程と言えます。
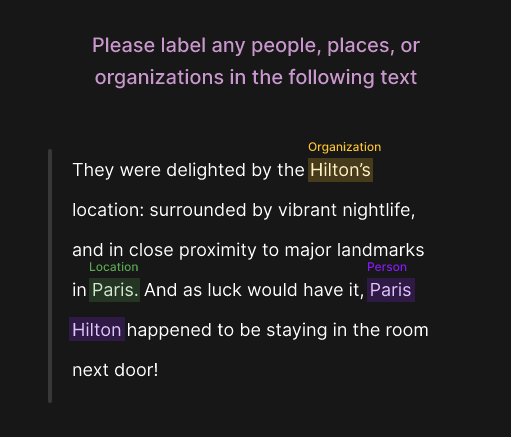
アノテーションとは簡単に説明するとAI用の画像などのデータに対してタグ付けやラベリングする作業のことです。以下の画像だと文字に対して、それぞれが組織なのか、場所なのか、人物なのかをタグ付けしています。
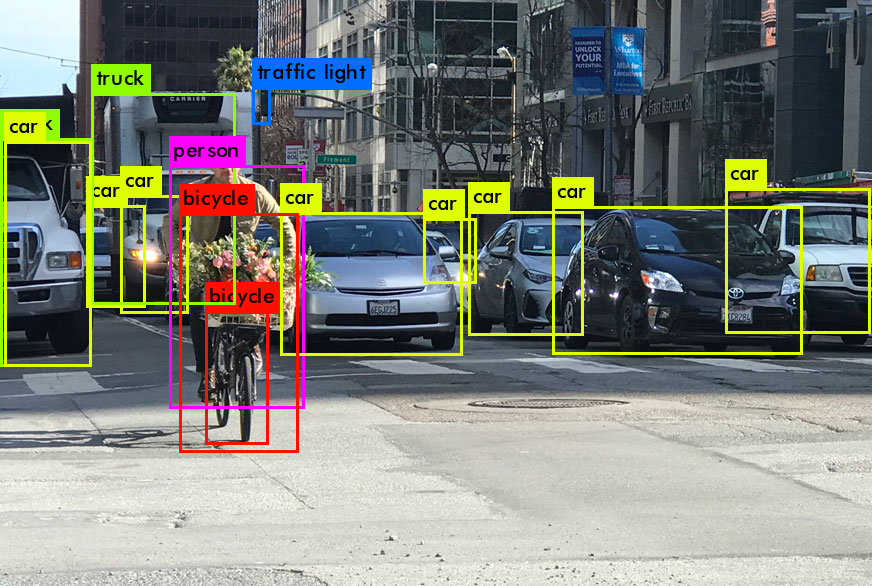
他にも作りたいモデルごとに音声に対して文字起こしをする作業や、以下のように画像の中でどの部分が人か車かなどを指定する作業など多岐にわたります。
最先端でクールと思われているような機械学習ですが、こういった単純労働の作業工程がペインとして存在しています。
このように集められるAI用のデータセットとラベリングの市場は拡大しています。
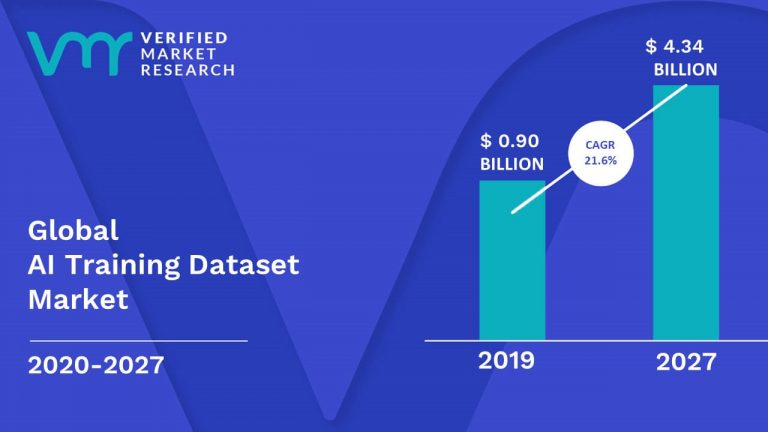
Verified market researchによるとグローバルで2019年時点で$0.9B(約1000億円)でCAGR21.6%の成長をしており、2027年には$4.34B(約4700億円)のマーケットになると予想されています。
同様に面倒なアノテーション作業を効率化するアノテーションツールのマーケットも今後伸びていくと予想されています。
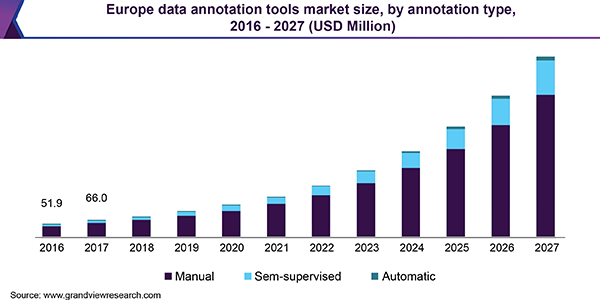
画像はヨーロッパの市場ですが、Grand view researchによるとアノテーションツールのマーケットは2019年時点ではグローバルで$390Mで、CAGR26.9%で成長すると予想されており、2027年時点では$2,570Mの市場規模になるそうです。
アノテーション市場の雄Scale AI
アノテーション作業は膨大な工数がかかり、また外注するとデータの質が安定しなかったり、膨大なマージンを取られたり、時間がかかるというペインが存在します。
言ってしまえばできることならやりたくないアノテーション作業ですが、上記のペインに着目し安く質の高いデータを提供するユニコーン企業がScale AIです。
Scale AIは現在未上場で時価総額$7.3B(約8000億円)で社長はAlexander Wang氏でなんと23歳です。直近ラウンドはグロースファンドのTigerGlobalがリードとして入っています。
顧客の大半は自動運転の企業でWaymo,Cruise,Uber,Lyftなどで、Airbnbやflexport,Squareなどのテックカンパニーも顧客になっています。
仕組みとしてはAPI経由で音声や映像などをScale AIに送るとソートトラベル付けをし、人力でクオリティチェックをして戻してくれるようになっています。
アノテーションのニーズは例えば犬を塗りつぶすなどの誰でも可能なタスクの場合は人件費の安い国へオフショアで依頼され、腫瘍を画像から発見するAIを作るなど専門的な場合は医師等の専門家にアノテーションしてもらう必要があったりと、最適なアノテーション会社を探すのが難しいという課題がありました。
Scale AIはこれらの会社を束ね最適な企業に外注し、データの精度やバイアスがないか(例えば特定の事例が足りなくないか)などを判断するツールもデータと合わせて提供することでバリューを出しています。
アノテーションの未来
Scale AI以外にもHive,Cloudfactory,Samesource,Labelboxなどがこの領域で活躍しています。Labelboxはデータラベリングタスクを管理するSaaSを提供しておりA16zから$25M調達しました。
A16zはLabelBoxはAI/機械学習業界のGitHubになると考えているようです。ご存知の通りGitHubはソースコードの管理をできるリポジトリであり、オープンソースとして様々なソースを試すことが可能です。
同様のことがLabelBoxにより実現され、データの管理だけでなく機械学習のモデルやアノテーションデータがオープンソース化される未来があるのかもしれません。
ここまでは海外の事例をお話ししましたが、日本でも複数プレイヤーが立ち上がっており、弊社でもアノテーションマーケットに挑むAPTO社へ投資をしています。
APTOはC側にharBestというアプリを提供し、ユーザーはアノテーションの作業をすることでamazonギフト券に交換できるポイントがもらえます。

B側はScale AIなどと同様に独自のアルゴリズムで品質チェックをしたアノテーションデータの収集とモデル構築、運用が可能なMLOpsのSaaSのharBest for Dataを提供する企業です。
従来オフショアでデータセットを数万件集めるのに数百万円かかっていたものがharbestを用いると、クラウドワーカーに直接依頼できるため数十万円でデータを短期間で集めることが可能です。
また、オートアノテーションというアノテーションを一部自動化する技術も保有しているという強みも存在します。
このブログではAIに対するツルハシがアノテーション関連の企業であると比喩表現しましたが、正確にはアノテーションデータはツルハシによって掘り起こされる金ではなく、産業革命における石炭に喩えられると思います。
機械学習のモデルは一度データを学習させれば一生使えるものではなく、徐々に精度が悪化し、使えなくなるためその都度新しいデータという名の石炭を用いてモデル学習するというメンテナンスが必要です。
メンテナンスやビジネスへの組み込みプロジェクト全体をMLOpsと呼ぶのですが、AI事情の立ち上がりに合わせて裏ではアノテーション周りとMLOpsへのニーズは今後さらに高まると考えており、非常に注目しています。
ANOBAKAはシードからアーリーステージのスタートアップに投資するベンチャーキャピタルです。現在、95社ほど投資しています。
起業家の方、ぜひ連絡ください!気軽に壁打ちしましょう!
twitter(@eni_naka)のDMにてお待ちしております。
ソース
https://fortune.com/2020/02/04/artificial-intelligence-data-labeling-labelbox/



